Dynatrace im Test: Server- & Website-Monitoring leicht gemacht
EIN TESTBERICHT
von David Wurm ![]() am 23. August 2021, 11:27
| Kommentar schreiben
am 23. August 2021, 11:27
| Kommentar schreiben
Für IT-Admins verursachen sie teilweise schlaflose Nächte und trotzdem werden sie geliebt: Monitoring-Tools. Sei es für die Server-Infrastruktur, Anwendung, Webseite oder den Cluster in der Cloud – Dynatrace will Admins das Leben leichter machen. Und dabei ganz anders als andere Monitoring-Tools agieren. Wie? Das klären wir im Test.
Viele Monitoring-Tools wie Nagios & Co. machen ihren Job gut, keine Frage. Sie schicken rechtzeitig Benachrichtigungen, wenn die Festplatte voll wird, der Arbeitsspeicher angefüllt ist oder die CPU ausgelastet ist und einiges mehr. Auch, dass die Anwendung, Server oder Webseite derzeit nicht erreichbar ist, langsamer lädt als vorher oder der Server einen anderen 5xx Error wirft. Der Ursache dieser Probleme muss man aber immer selbst auf den Grund gehen. Stundenlanges durchforsten von Logs – vielleicht auch in der Nacht – ist der pure Wahnsinn. Dynatrace will genau diesen Punkt verbessern und hinter die Kulissen blicken: Was ist da genau los? Was verursacht diesen Fehler? Gab es Konfigurationsänderungen?
Um zu testen, ob die Software seine Versprechen auch wirklich halten kann, haben wir Dynatrace auf unsere Server geschmissen und es einfach laufen lassen. Wie sich das Monitoring-Tool im Alltag schlägt, klären wir jetzt – selbstverständlich auf Herz und Nieren vom TechnikNews Sysadmin ausprobiert.
Zum Abschnitt springen
Was wir in diesem Test klären
Dynatrace kann echt viele Dinge, die den Rahmen hier sprengen würden. Da die TechnikNews Infrastruktur grundsätzlich relativ einfach ist, legen wir unseren Fokus wir uns hier auf das Monitoring von Webseiten auf einem Linux-Server. Den Einsatz von Dynatrace in Kubernetes-Clustern, AWS, Azure und mehr lassen wir mal außen vor.
Was normale Monitoring-Tools bei TechnikNews tun
Gehen wir unseren Test konkret an und reden wir vom Ist-Stand: Wir bei TechnikNews verwenden eine Kombination aus Nagios und eigener Software im Hintergrund als Webseiten-Crawler für das Dienste-Monitoring. Mit diesem Setup überwachen wir alle unsere Server und Webseiten. Bei Nichterreichbarkeit eines Dienstes können wir so schnell eingreifen und das Problem in Ordnung bringen. Mittels Webhook pusht das TechnikNews Monitoring die Incidents direkt auf das Smartphone via Telegram-Bot, schreibt den Fehler via API automatisch auf unsere Status-Seite und schickt mir Details zusätzlich per E-Mail aus.
Ist nun ein bestimmter Dienst nicht erreichbar, beginnt die Suche nach der Ursache. Die Identifizierung des Problems liegt meistens darin, die entsprechenden Logs zum auftretenden Zeitpunkt anzuschauen. Oder man macht es sich gemütlich, startet den Server neu und hofft einfach, dass es wieder funktioniert. So leicht sollte man es sich auch nicht machen – schließlich muss herausgefunden werden, was eigentlich passiert ist und wie es passieren konnte. Gibt es da eine Alternative? Nein – dachte ich zumindest. Bis ich Dynatrace kennenlernen durfte.
Was Dynatrace bei TechnikNews tut
Kommen wir zum spannenden Part, was tut Dynatrace jetzt eigentlich? Grundsätzlich, egal, in welcher Konstellation bei Euch die Dienste laufen (Kubernetes, Cluster, Virtualisierung) – Dynatrace sollte für fast alle Use Cases funktionieren. Außer es wird sehr veraltete Software auf den Servern eingesetzt, dann könnte das Monitoring eventuell nicht so gut funktionieren wie gewünscht. Es empfiehlt sich generell, auch hier bei Dynatrace, neue Software auf dem Server immer in einer Dev-Umgebung auszuprobieren. Nur so ist ein reibungsloser Betrieb beim Umstieg auf die Produktivumgebung gewährleistet.

Dynatrace will mit eine All-in-one Monitoring-Lösung bieten. (Bild: Dynatrace)
Dynatrace ist bei TechnikNews mittlerweile für das gesamte Monitoring zuständig. Es läuft auf unserem Windows-Server, auf unseren Linux-Systemen und dem TechnikNews Hostsystem mit der Virtualisierungssoftware Proxmox. Mit all diesen Umgebungen kann Dynatrace problemlos umgehen. Auch wenn Dynatrace Proxmox-spezielle Funktionen nicht genau überwachen kann (Dynatrace unterstützt aber beispielsweise VMware).
Nichtsdestotrotz wird Dynatrace im laufenden Betrieb intelligenter und versucht das System zu verstehen. Sollte beispielsweise die CPU-Last jeden Tag um 12 Uhr hoch sein, lernt Dynatrace das und schickt keine extra Monitoring-Benachrichtigung. Lädt die Webseite einige Sekunden länger als üblich oder braucht ein Dienst länger bei seiner Ausführung, meldet sich Dynatrace gleich per App-Push, E-Mail oder Webhook. Grundlage für diese Mitteilungen sind Überschreitungen der „Baseline“ (die typische Ladezeit/Ausführungszeit), welche Dynatrace nach mehreren Wochen Betrieb bekannt sein sollte.
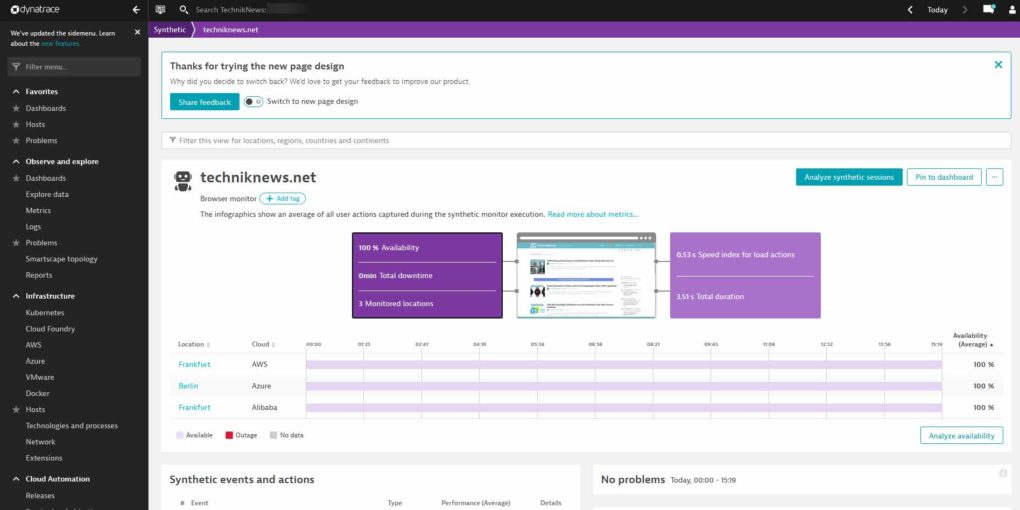
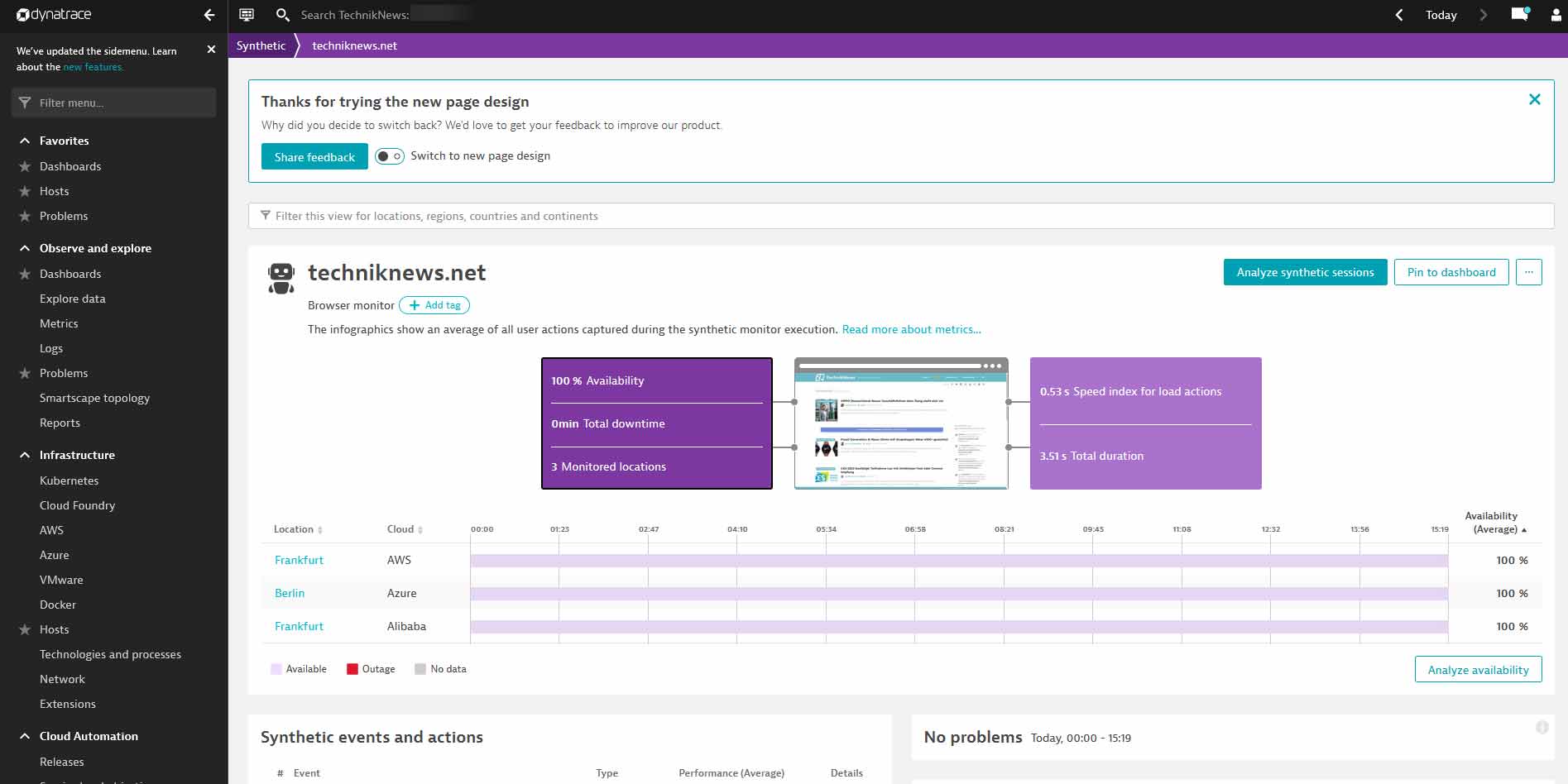
Synthetic Monitoring
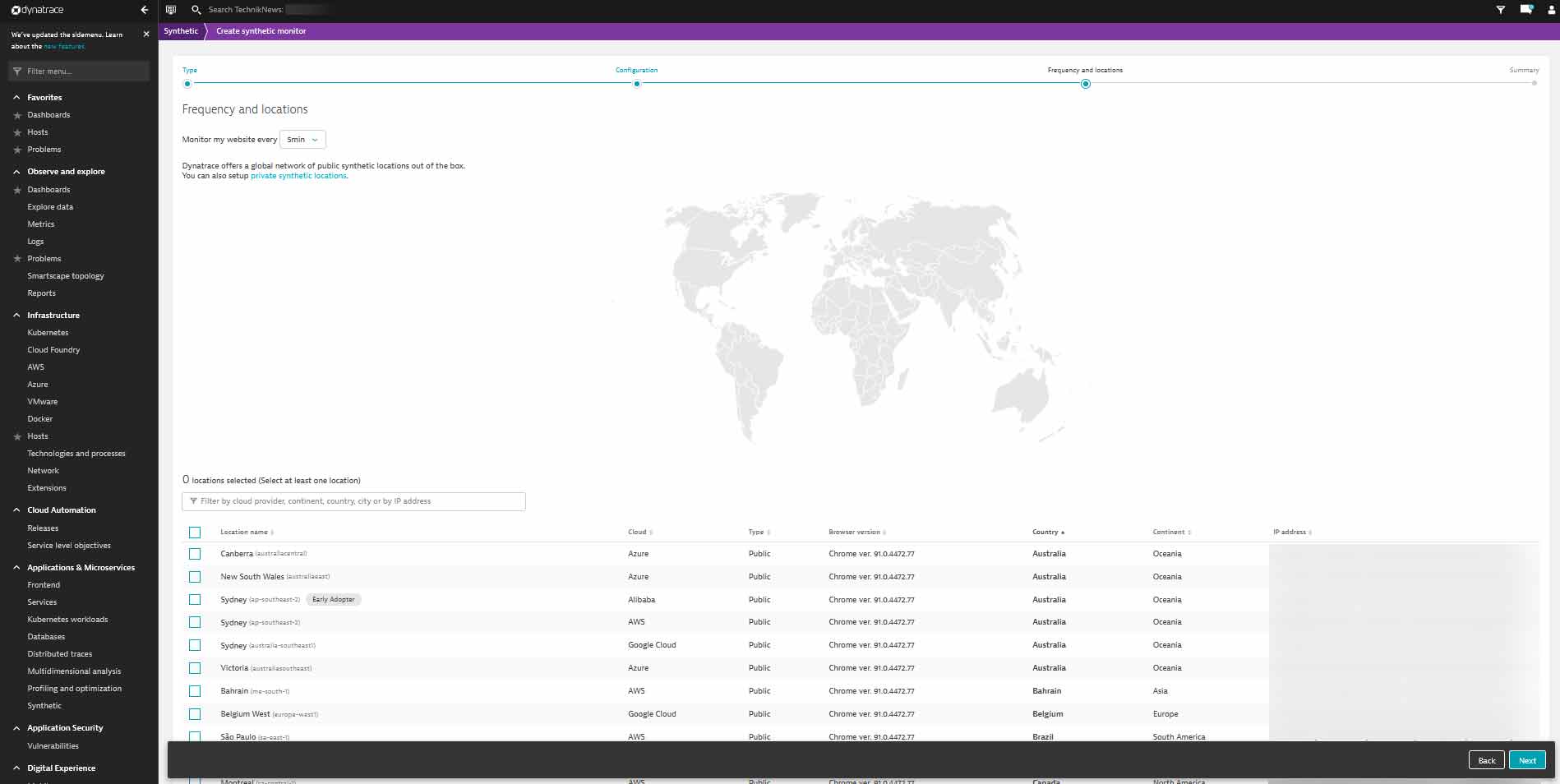
Mit dem sogenannten „Synthetic Monitoring“ könnte Dynatrace unser bisheriges Monitoring-System als All-in-One-Tool komplett ersetzen. Dynatrace gibt sich hierbei wie ein ganz üblicher Client (Desktop oder mobiles Gerät) aus und greift in einem Monitoring-Vorgang von bis zu drei verschiedenen Regionen auf eine bestimmte URL zu. Einstellungen zum Client und User-Agent können ganz individuell vorgenommen werden – sei es zum Beispiel ein zugreifendes Apple iPhone X oder ein Samsung Galaxy S20. Anschließend kann man aus knapp 100 verschiedenen Datacentern wählen. Maximal drei können in einem Schritt ausgewählt werden. Von diesen wird dann die angegebene URL in einstellbaren Intervallen von fünf Minuten bis zu vier Stunden abgerufen.
-
- Dynatrace kann im vordefinierten Intervall bestimmte URLs abrufen und monitoren. (Bild: TechnikNews)
-
- Dabei kann der zu verwendende Client und weitere Einstellungen zum User-Agent festgelegt werden. (Bild: TechnikNews)
-
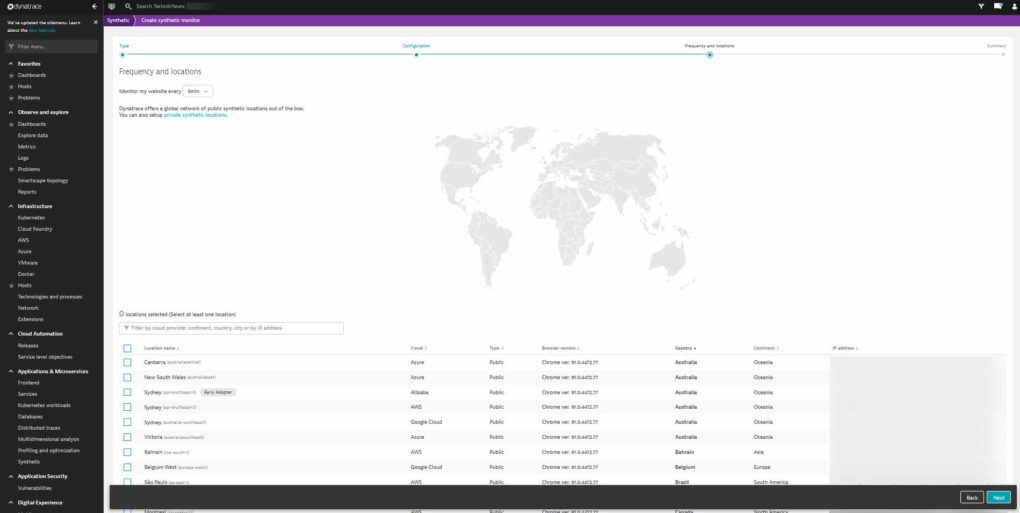
- Knapp 100 verschiedene Rechenzentren können für das Monitoring ausgewählt werden. (Bild: TechnikNews)
Sollte dabei die Ladezeit in einem definitierten Zeitraum (etwa 5 Minuten) um beispielweise eine Sekunde überschritten werden, wird ein Problem geöffnet und man erhält eine Benachrichtigung. Was mit Problemen genau gemeint ist, klären wir gleich – hold on.
Dynatrace Problemanalyse
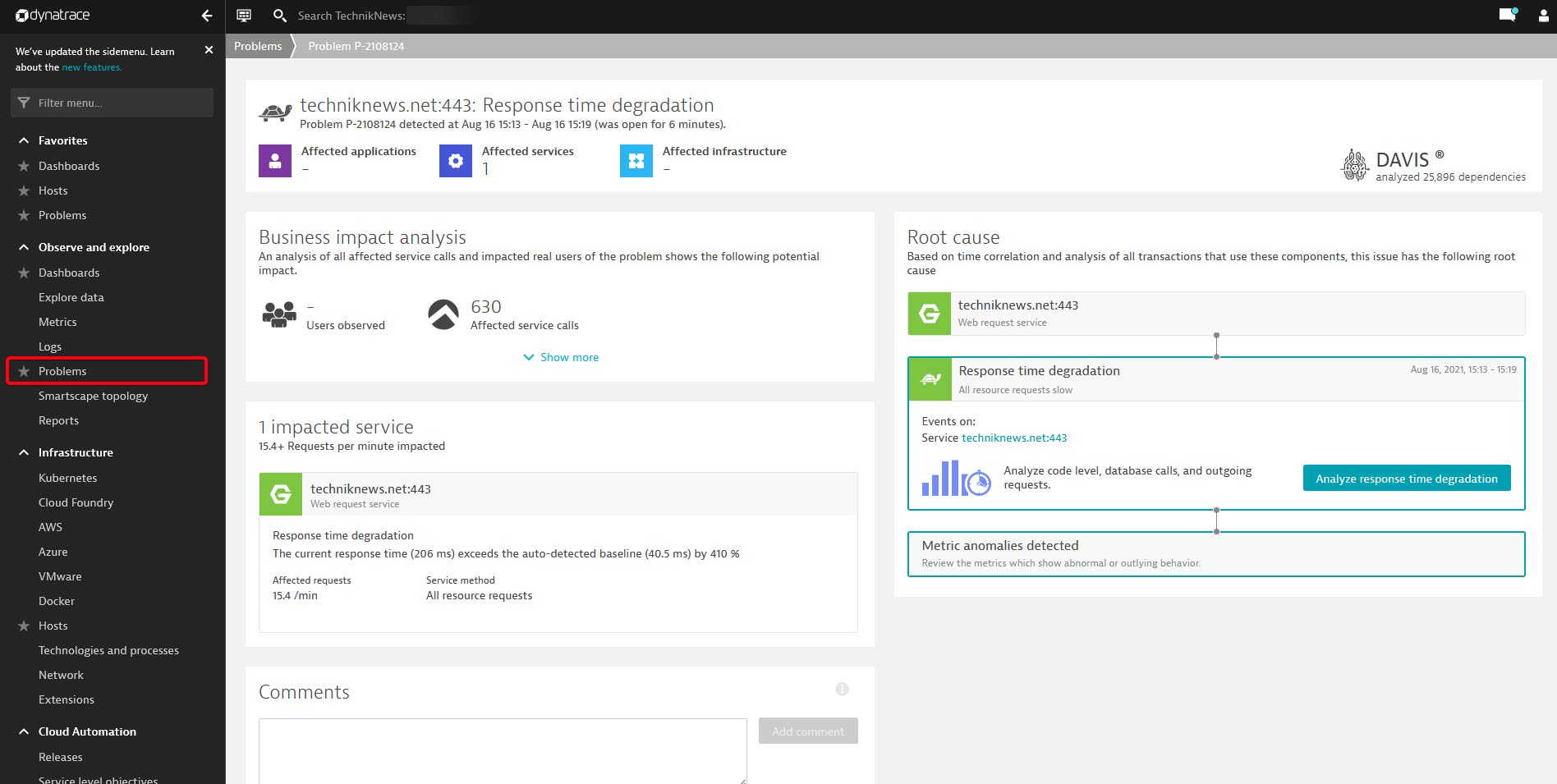
Über den Problem-Viewer lässt sich die in diesem Fall längere Ladezeit der TechnikNews Homepage gleich identifizieren. (Bild: TechnikNews)
Sollte ein Problem auftreten, wird ein neues Problem in Form eines „Tickets“ in Dynatrace angelegt. Gleichzeitig kann man sich per E-Mail, Push-Notification mit der Dynatrace-App, Slack und vielen weiteren Diensten via Webhook benachrichtigen lassen. Auch kann Dynatrace beispielsweise für die IT direkt ein Jira-Ticket heraus generieren. Die E-Mail enthält einen Link zur Problemansicht, welche man in Dynatrace unter „Problems“ findet.
In diesem Fall ist eine „Response time degradation“ die Ursache für die Meldung. Im Bereich „impacted service“ finden wir auch gleich weitere Details dazu. So hat unser Webserver zum Ausliefern der TechnikNews Homepage zwischen 15:13 und 15:19 Uhr bei 15,4 Requests in der Minute statt 40,5 Millisekunden hier 206 Millisekunden benötigt. Ein Klick auf „Analyze response time degradation“ liefert auch gleich den Übeltäter. Dieser wurde von Davis – der Dynatrace KI – mithilfe der Auswertung von 25.000 Zusammenhängen auf unserem System ermittelt.
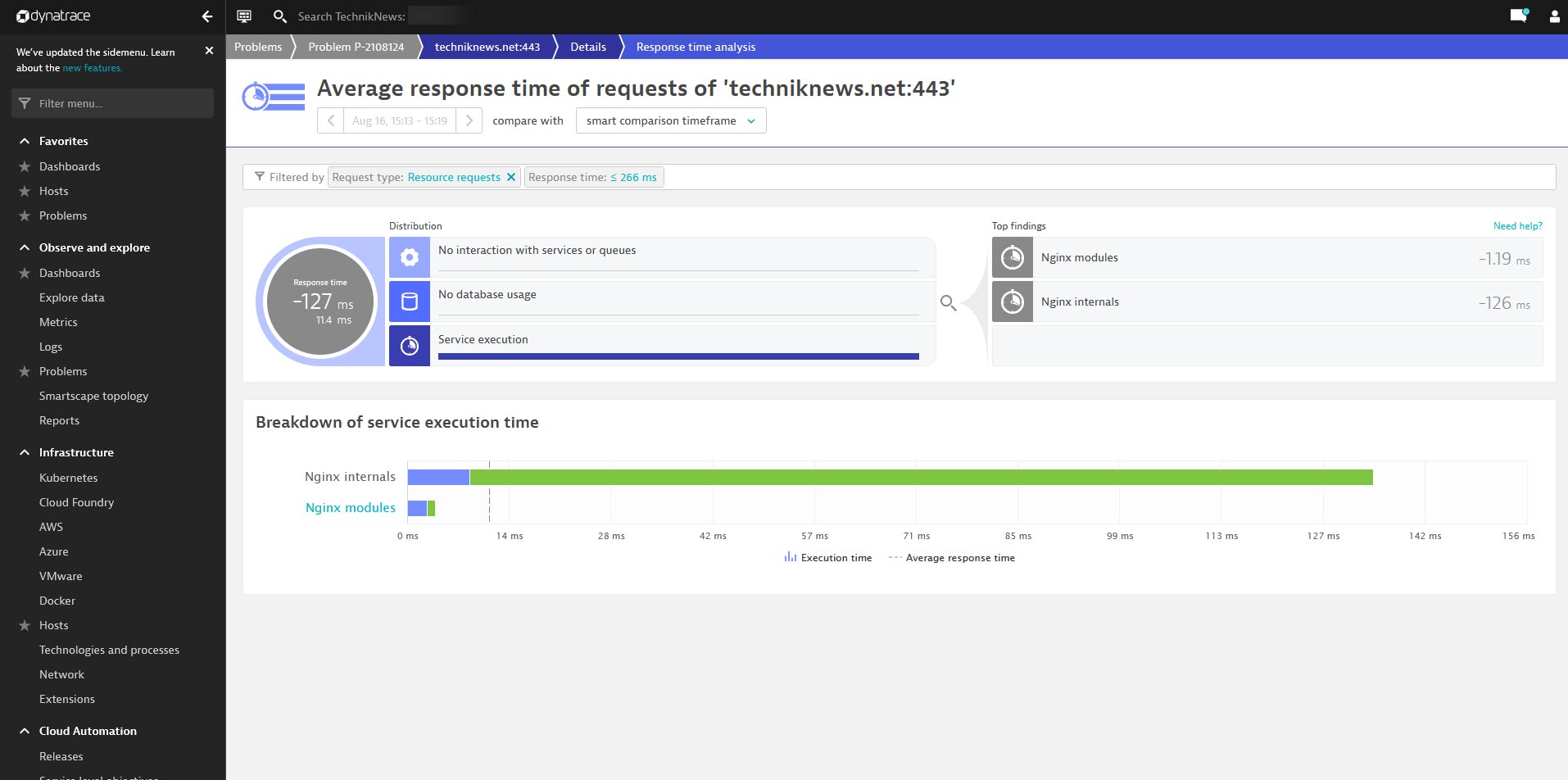
Die Dynatrace KI „Davis“ hat hier den Übeltäter der längeren Ladezeit ermittelt. (Bild: TechnikNews)
Hier war Nginx selbst das ausschlaggebende Problem, welches zu längeren Ladezeiten geführt hat. Da wir zu diesem Zeitpunkt Updates an Nginx durchgeführt haben, ist diese Analyse völlig zutreffend und der Übeltäter somit für uns gleich bekannt. In einem weiteren Fall war ein langsamer Festplattenzugriff laut Dynatrace die Ursache – was für uns auch schnell erledigt war, da zeitgleich ein Backup gelaufen ist.
Viele Dienste, viele Problemmeldungen zu Beginn
Zu Beginn gibt es so gut wie noch keine Problemmeldungen, da das Tool das System genauer kennenlernen muss. Ist diese Lernphase von einigen Wochen abgeschlossen, lernt das Monitoring-Tool so richtig zu funktionieren, schickt anfangs ziemlich viele Meldungen und öffnet Problem-Tickets. So, wenn etwa ein Dienst einige Millisekunden länger lädt, ein TCP-Connect bei einem Dienst für wenige Sekunden auf 0 Prozent sinkt – alles Dinge, die bei einem Produktivsystem passieren können und durchaus wenig bzw. keinerlei Einfluss auf die betriebenen Dienste haben.

Für weniger Benachrichtigungen und E-Mails kann man die Schwelle für Mitteilungen einstellen. (Bild: TechnikNews)
Selbstverständlich kann man all diese Meldungen auf der jeweiligen Detailseite des Prozesses ausschalten, es wäre aber gut, einen Wizard zu haben, der einen von Beginn an die Benachrichtigungen gleich konfigurieren lässt. Ob TechnikNews jetzt einige Millisekunden länger lädt, beeinträchtigt nicht wirklich. Somit haben wir die Einstellungen in der „Anomaly Detection“ angepasst. Beispielweise wollen wir erst benachrichtigt werden, wenn TechnikNews um eine Sekunde länger lädt, es mindestens 50 Requests in der Minute betrifft und das Problem mindestens für fünf Minuten besteht.
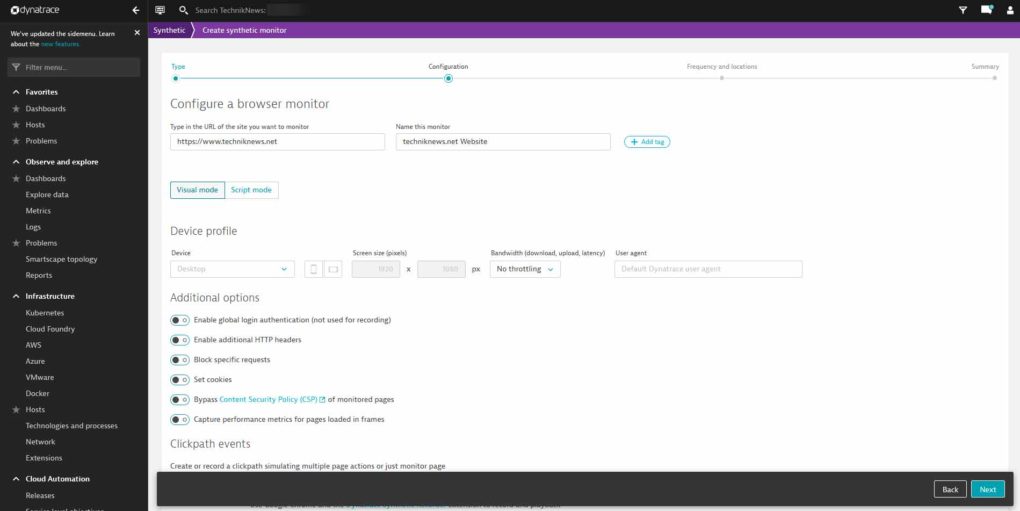
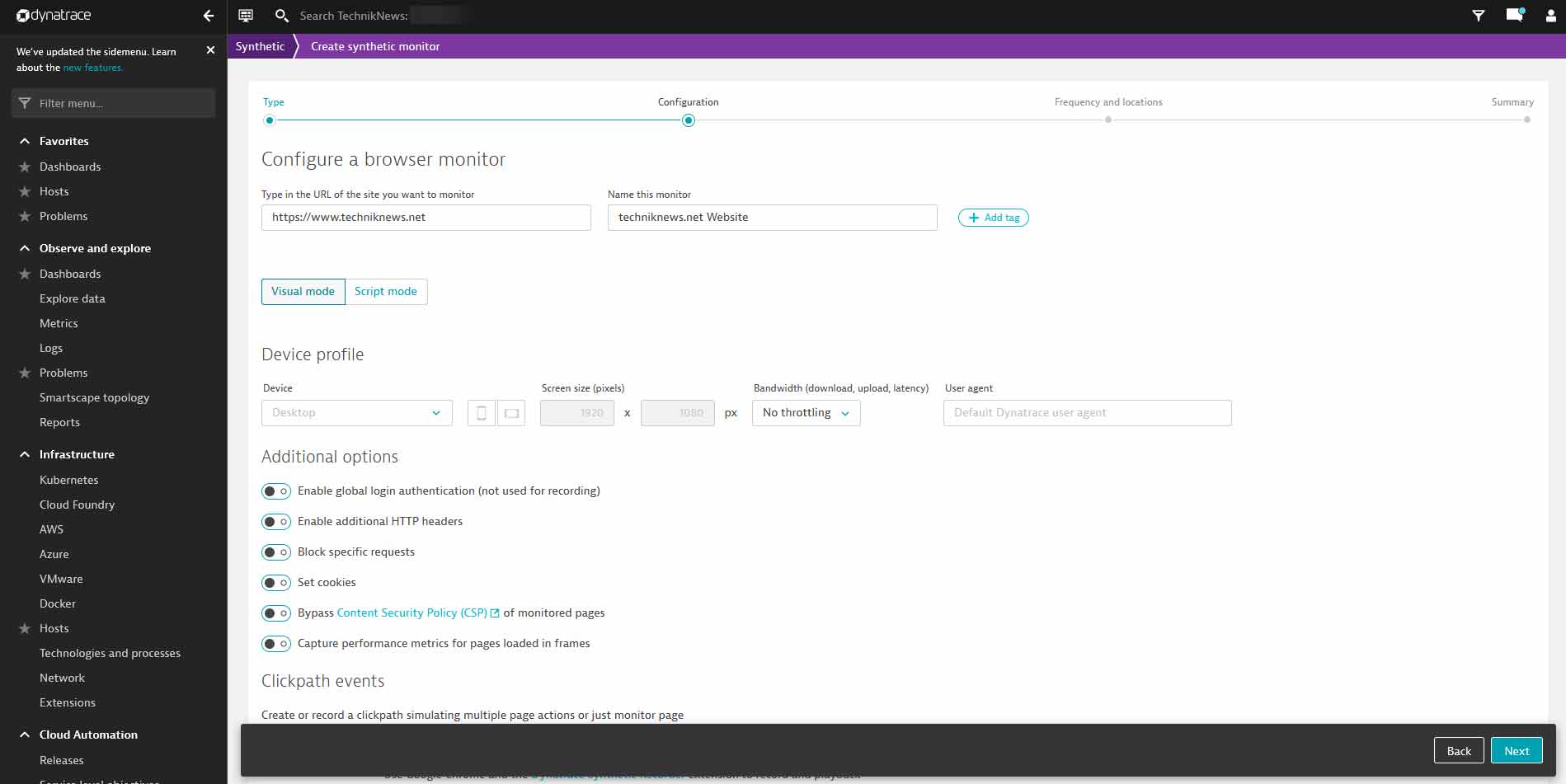
Installation von Dynatrace in Sekunden
-
- Der Dynatrace OneAgent läuft auf zahlreichen Systemen. (Bild: TechnikNews)
-
- Die Installation selbst ist anschließend in wenigen Sekunden erledigt. (Bild: TechnikNews)
Die Installation auf unserem Linux-Webserver mit Ubuntu war innerhalb von wenigen Sekunden erledigt, anschließend muss man den Server noch neu starten, also alles innerhalb weiterer weniger Sekunden erledigt. Dies ist notwendig, damit sich Dynatrace direkt zwischen OS und den jeweiligen Diensten/Prozessen (Apache, PHP, …) einklinken kann. Dafür wird einfach unter dem Menüpunkt „Deploy Dynatrace“ der sogenannte „OneAgent“ (der Dynatrace Client) am Server installiert. Unterstützt werden gängige Systeme wie Windows, Linux, Kubernetes, AWS Lambda und viele weitere Umgebungen.
Doch nicht alles ist ganz perfekt
Wie jedes Tool gibt es auch bei Dynatrace in einigen Punkten noch etwas Luft nach oben. So sollte die Struktur der Einstellungen und der Seitenleiste überarbeitet werden, die Einarbeitung in Dynatrace ist durch die sehr verschachtelte Menüführung sehr kompliziert. Zwar machen die Entwickler in der neuesten Version 1.221 das Menü schon deutlich besser, man wird hier aber noch ein paar Verbesserungen angehen müssen.
Rechtesystem
Auch das Rechtesystem ist nicht perfekt. Es sind sehr viele Einstellungen notwendig, um einen zweiten Nutzer in seinen Account einzuladen, welcher etwa nur einen Server der Infrastruktur sehen darf. Hat man dafür die sogenannten „Management zones“ und „Monitoring groups“ erst angelegt und dem jeweiligen Nutzer zugeweisen, gibt es bei Dingen wie der Problemanalyse und Komponenten-Zusammenhängen teilweise Probleme mit Berechtigungen. Praktisch wäre es, einem Nutzer direkt einem Server zuordnen zu können und alle dem Server zugehörigen Prozesse auch zur Anzeige des Nutzers freizugeben.
Fazit
Ob Dynatrace für den Hobby-Serverbetreiber wirklich geeignet ist, darüber lässt sich streiten. Diese Zielgruppe will man aber auch nicht bedienen. Eher geht es um große Kunden, deutlich komplexere Infrastruktur und Dienste, welche Hochverfügbar sein müssen. Hier punktet Dynatrace mit der einfachen Installation, unendlichen Einstellungsmöglichkeiten, der Problemanalyse mit Berücksichtigung aller Geschehnisse auf dem System, welche mit der Zeit immer intelligenter wird, und dem verschwindend geringen Ressourcenverbrauch des OneAgent.
Im Grundsatz kann man sagen, dass Dynatrace auch „nur“ ein Monitoring-Service ist. Ja, allerdings kann Dynatrace noch vieles mehr. Man bekommt nicht nur Mitteilungen über Probleme, sondern auch gleich die Ursache mit den betroffenen Requests/Diensten direkt in einer detaillierten Übersicht angezeigt. Ein übliches Monitoring würde über das Problem aufmerksam machen, die Analyse des Problems muss der jeweilige IT-Admin übernehmen. Was bei einer einfachen Infrastruktur wie bei TechnikNews teilweise schon schwer fällt, gestaltet sich komplexeren Systemen noch schwieriger. Genau hier kommt Dynatrace ins Spiel. Auch wenn die Dynatrace-Preise am ersten Blick teuer scheinen mögen, die gesparte Arbeitszeit mit Überstunden und vielen Tassen Kaffee dürften die Preise aber gleich wieder rechtfertigen.
-
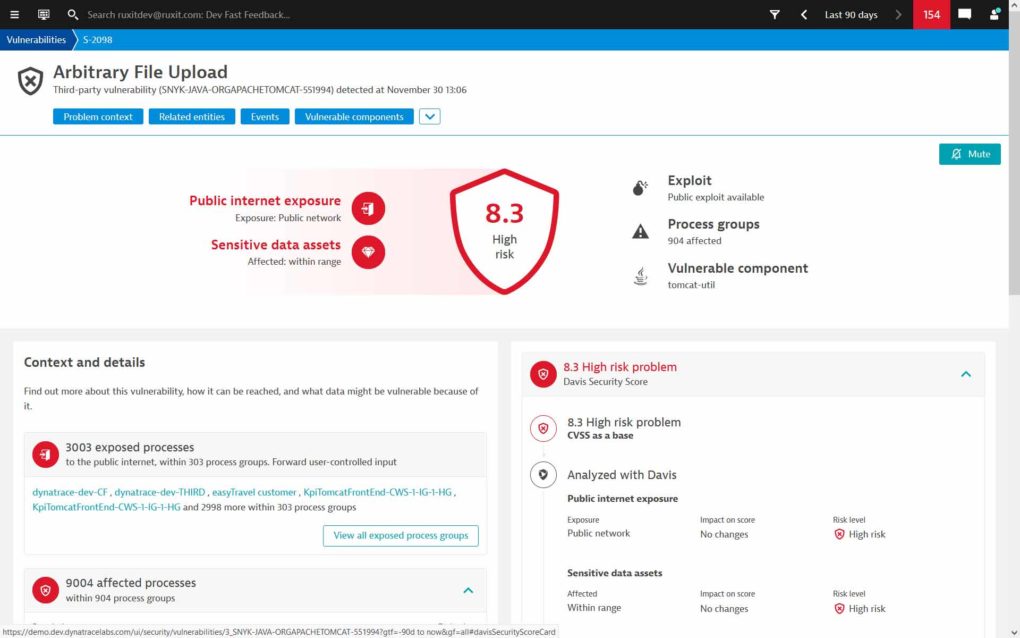
- Künftig wird Dynatrace den Sicherheitsstatus der Infrastruktur anzeigen. (Bild: Dynatrace)
-
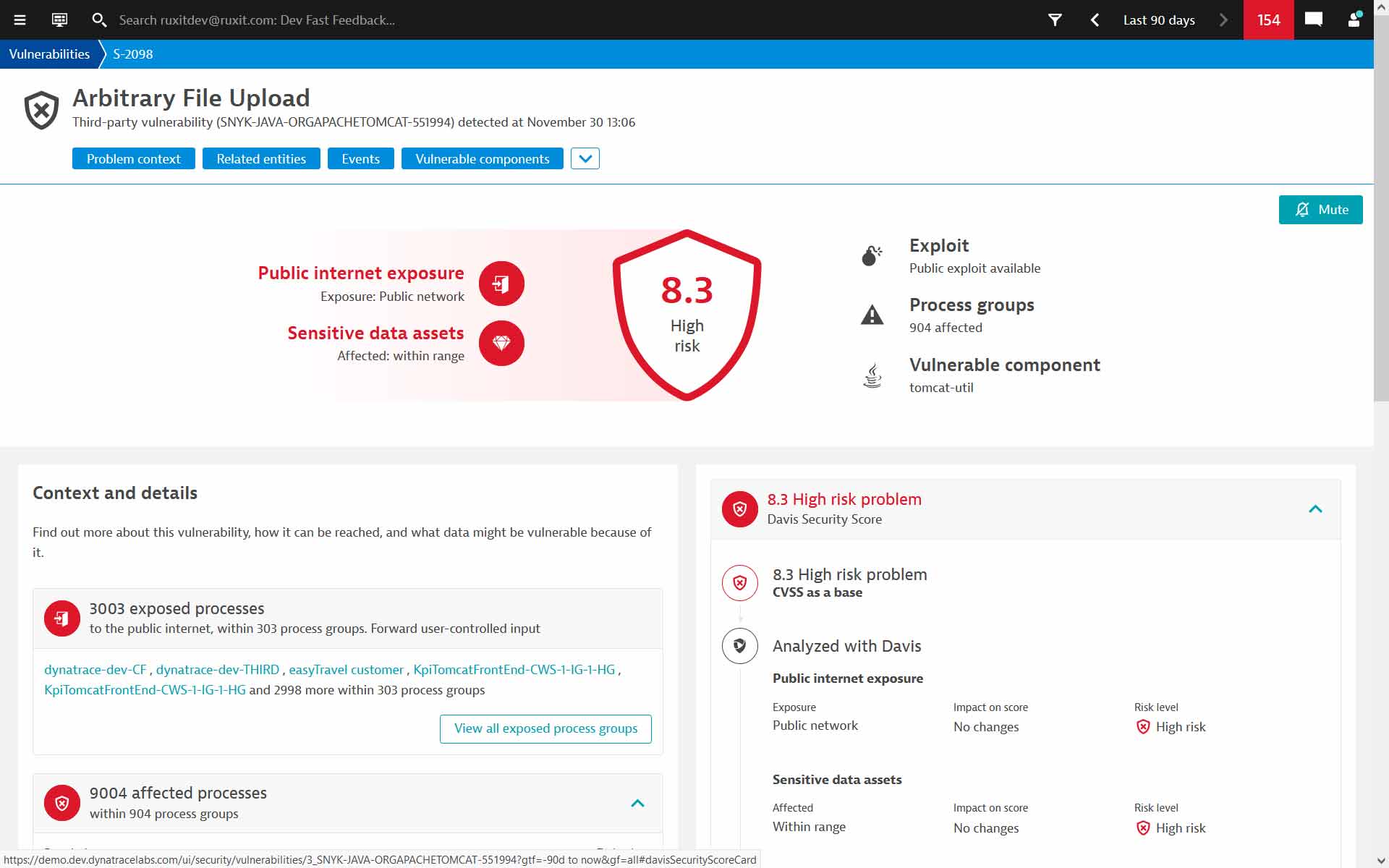
- Der IT-Admin erhält genaue Auflistungen über bekannte Sicherheitslücken von eingesetzten Diensten am Server. (Bild: Dynatrace)
-
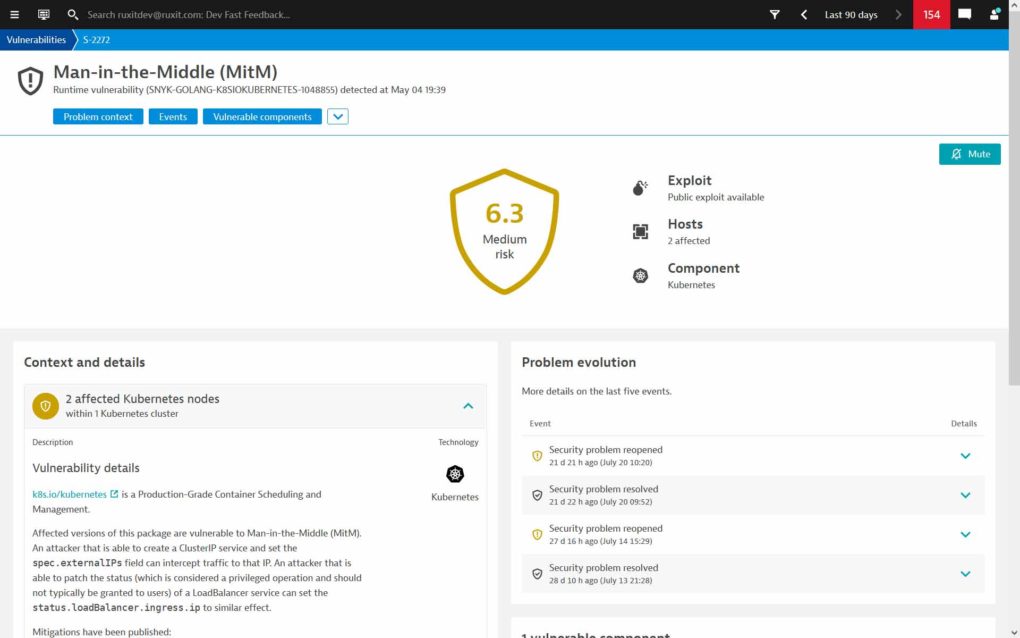
- Für jede Sicherheitslücke werden zudem weitere Hinweise dazu angeboten. (Bild: Dynatrace)
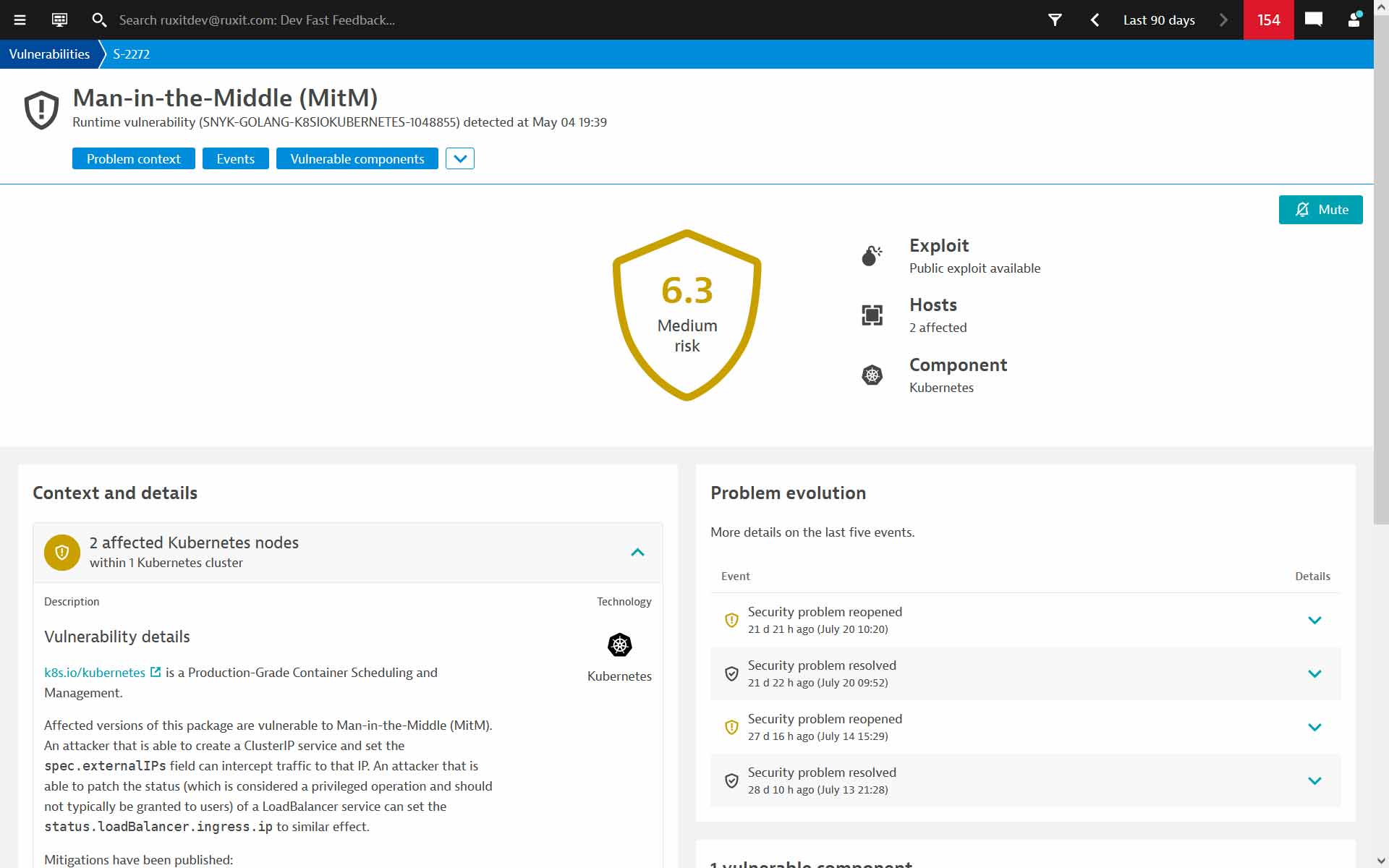
Dynatrace wird auch weiterhin das Monitoring von TechnikNews übernehmen. Zudem wird die künftige Entwicklung des Tools – besonders im Bereich der Vulnerability-Erkennung (Monitoring-Meldungen über Sicherheitslücken bei eingesetzten Diensten) – noch ziemlich spannend.
Transparenzhinweis: Dynatrace wurde mir für TechnikNews im Rahmen eines Ferialpraktikums zum Test zur Verfügung gestellt. Dennoch spiegelt dieser Artikel ausschließlich meine eigene Meinung wider.